Fine-tuning a VLM using LoRA
Prepare your vision dataset
vision datasets must be in JSONL format in OpenAI-compatible chat format.
Each line represents a complete training example.Dataset Requirements:You can use the following script to automatically convert your dataset to the correct format:
- Format:
.jsonlfile - Minimum examples: 3
- Maximum examples: 3 million per dataset
- Images: Must be base64 encoded with proper MIME type prefixes
- Supported image formats: PNG, JPG, JPEG
messages array where each message has:role: one ofsystem,user, orassistantcontent: an array containing text and image objects or just text
Basic VLM Dataset Example
If your dataset contains image urls
Images must be base64 encoded with MIME type prefixes. If your dataset contains image URLs, you’ll need to download and encode them to base64.- ❌ Incorrect
- ✅ Correct
Python script to download and encode images to base64
Python script to download and encode images to base64
Usage:
Advanced Dataset Examples
- Multi-image Conversation
- Multi-turn Conversation
Try with an Example Dataset
To get a feel for how VLM fine-tuning works, you can use an example vision dataset. This is a classification dataset that contains images of food with<think></think> tags for reasoning.- Download with curl
- Download with wget
Upload your VLM dataset
Upload your prepared JSONL dataset to Fireworks for training:
- firectl
- UI
- REST API
Launch VLM fine-tuning job
Create a supervised fine-tuning job for your VLM:For additional parameters like learning rates, evaluation datasets, and batch sizes, see Additional SFT job settings.VLM fine-tuning jobs typically take longer than text-only models due to the additional image processing. Expect training times of several hours depending on dataset size and model complexity.
- firectl
- UI
Monitor training progress
Track your VLM fine-tuning job in the Fireworks console.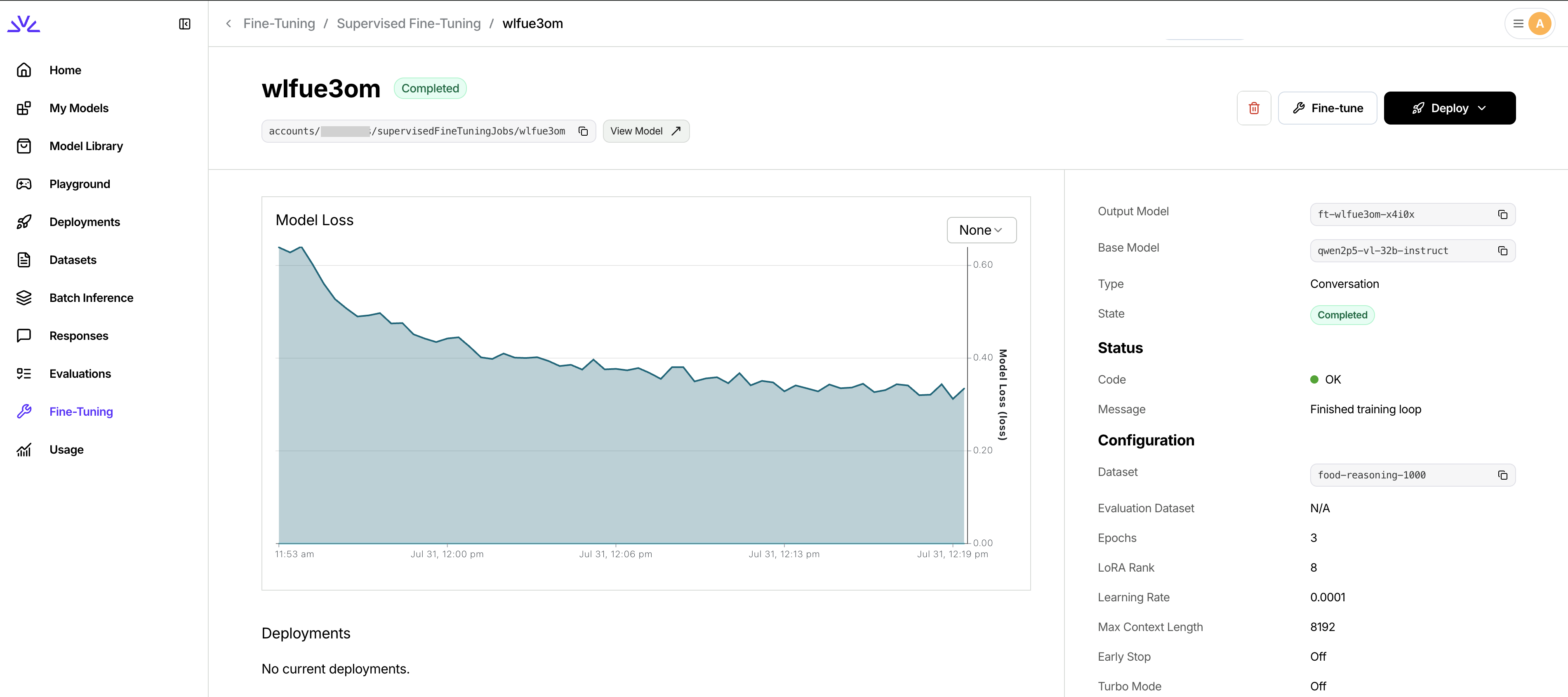
- Training loss: Should generally decrease over time
- Evaluation loss: Monitor for overfitting if using evaluation dataset
- Training progress: Epochs completed and estimated time remaining
Your VLM fine-tuning job is complete when the status shows
COMPLETED and your custom model is ready for deployment.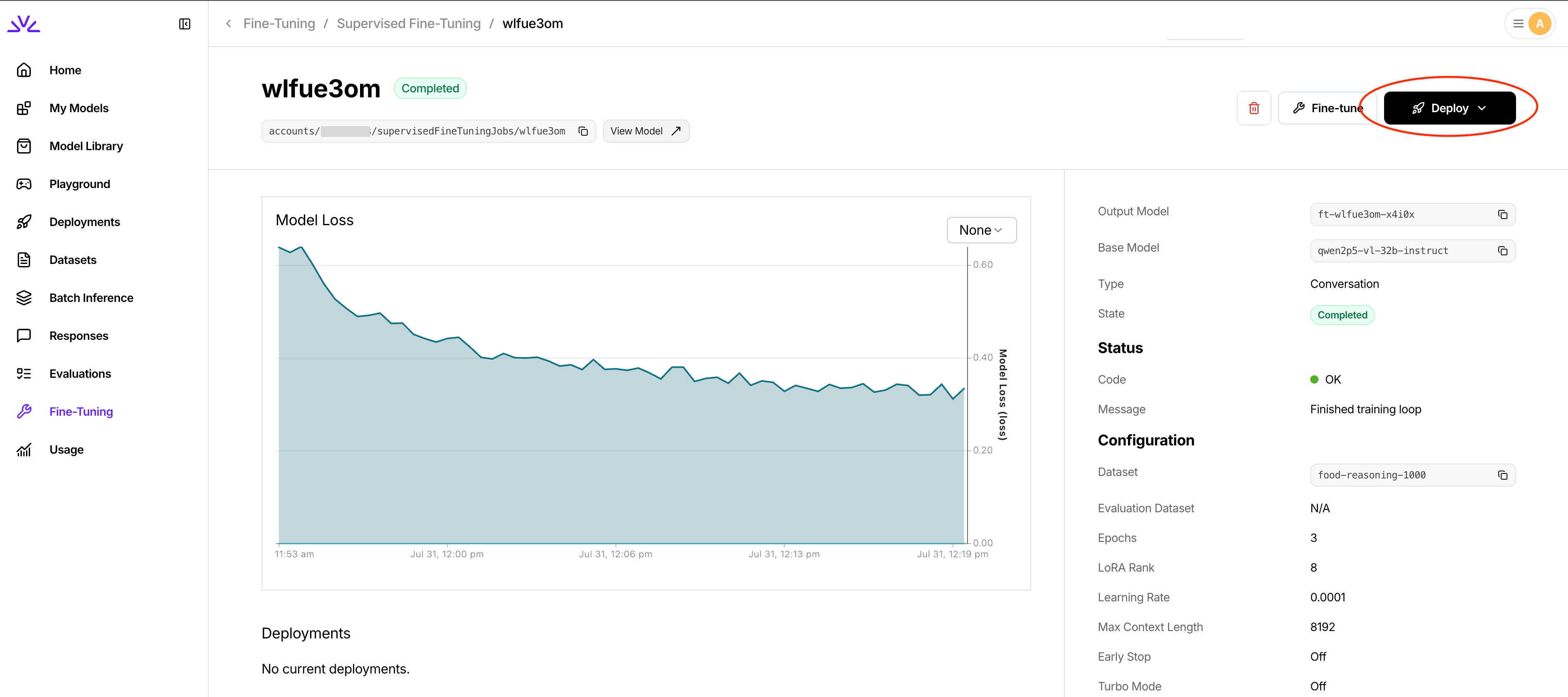
Advanced Configuration
For additional fine-tuning parameters and advanced settings like custom learning rates, batch sizes, and optimization options, see the Additional SFT job settings section in our comprehensive fine-tuning guide.Interactive Tutorials: Fine-tuning VLMs
For a hands-on, step-by-step walkthrough of VLM fine-tuning, we’ve created two fine tuning cookbooks that demonstrates the complete process from dataset preparation, model deployment to evaluation.VLM Fine-tuning Quickstart
Google Colab Notebook: Fine-tune Qwen2.5 VL on Fireworks AI
VLM Fine-tuning + Evals
Finetuning a VLM to beat SOTA closed source model
- Setting up your environment with Fireworks CLI
- Preparing vision datasets in the correct format
- Launching and monitoring VLM fine-tuning jobs
- Testing your fine-tuned model
- Best practices for VLM fine-tuning
- Running inference on serverless VLMs
- Running evals to show performance gains
Testing Your Fine-tuned VLM
After deployment, test your fine-tuned VLM using the same API patterns as base VLMs:Python (OpenAI SDK)